让问答更自然 - 基于拷贝和检索机制的自然答案生成系统研究
- 2017-05-15 15:43:39
摘要:让机器像人类一样拥有智能是研究人员一直以来的奋斗目标。由于智能的概念难以确切定义,图灵提出了著名的图灵测试(Turning Test):如果一台机器能够与人类展开对话而不能被辨别出其机器身份,那么称这台机器具有智能。图灵测试一直以来都被作为检验人工智能的象征。问答系统本身就是图灵测试的场景,如果我们有了和人一样的智能问答系统,那么就相当于通过了图灵测试,因此问答系统的研究始终受到很大的关注。
让机器像人类一样拥有智能是研究人员一直以来的奋斗目标。由于智能的概念难以确切定义,图灵提出了著名的图灵测试(Turning Test):如果一台机器能够与人类展开对话而不能被辨别出其机器身份,那么称这台机器具有智能。图灵测试一直以来都被作为检验人工智能的象征。问答系统本身就是图灵测试的场景,如果我们有了和人一样的智能问答系统,那么就相当于通过了图灵测试,因此问答系统的研究始终受到很大的关注。
传统知识问答都是针对用户(使用自然语言)提出的问句,提供精确的答案实体,例如:对于问句“泰戈尔的出生地在哪儿?”,返回“加尔各答”。但是,仅仅提供这种孤零零的答案实体并不是非常友好的交互方式,用户更希望接受到以自然语言句子表示的完整答案,如“印度诗人泰戈尔出生于加尔各答市”。自然答案可以广泛应用有社区问答、智能客服等知识服务领域。知识问答中自然答案的生成在具有非常明确的现实意义和强烈的应用背景。
 与返回答案实体相比,知识问答中返回自然答案有如下优势:
1. 普通用户更乐于接受能够自成一体的答案形式,而不是局部的信息片段。
2. 自然答案能够对回答问句的过程提供某种形式的解释,还可以无形中增加用户对系统的接受程度。
3. 自然答案还能够提供与答案相关联的背景信息(如上述自然答案中的“印度诗人”)。
4. 完整的自然语言句子可以更好地支撑答案验证、语音合成等后续任务。
但是让知识问答系统生成自然语言形式的答案并不是一件容易的事情。目前,基于深度学习的语言生成模型大多基于原始数据学习数值计算的模型,如何在自然答案生成过程中融入符号表示的外部知识库是一个大的挑战。另外,很多问句的回答需要利用知识库中的多个事实,并且一个自然答案的不同语义单元(词语、实体)可能需要通过不同途径获得, 回答这种需要使用多种模式提取和预测语义单元的复杂问句,给自然答案的生成带来了更大的挑战。
为了解决这些问题,中科院自动化所的何世柱博士、刘操同学、刘康老师和赵军老师在今年的 ACL2017 上发表了论文「Generating Natural Answers by Incorporating Copying and Retrieving Mechanisms in Sequence-to-Sequence Learning」,提出了端到端的问答系统 COREQA,它基于编码器-解码器(Encoder-Decoder)的深度学习模型,针对需要多个事实才能回答的复杂问句,引入了拷贝和检索机制,从不同来源,利用拷贝、检索和预测等不同词汇获取模式,获得不同类型的词汇,对应复杂问句中答案词汇的不同部分,从而生成复杂问句的自然答案。
与返回答案实体相比,知识问答中返回自然答案有如下优势:
1. 普通用户更乐于接受能够自成一体的答案形式,而不是局部的信息片段。
2. 自然答案能够对回答问句的过程提供某种形式的解释,还可以无形中增加用户对系统的接受程度。
3. 自然答案还能够提供与答案相关联的背景信息(如上述自然答案中的“印度诗人”)。
4. 完整的自然语言句子可以更好地支撑答案验证、语音合成等后续任务。
但是让知识问答系统生成自然语言形式的答案并不是一件容易的事情。目前,基于深度学习的语言生成模型大多基于原始数据学习数值计算的模型,如何在自然答案生成过程中融入符号表示的外部知识库是一个大的挑战。另外,很多问句的回答需要利用知识库中的多个事实,并且一个自然答案的不同语义单元(词语、实体)可能需要通过不同途径获得, 回答这种需要使用多种模式提取和预测语义单元的复杂问句,给自然答案的生成带来了更大的挑战。
为了解决这些问题,中科院自动化所的何世柱博士、刘操同学、刘康老师和赵军老师在今年的 ACL2017 上发表了论文「Generating Natural Answers by Incorporating Copying and Retrieving Mechanisms in Sequence-to-Sequence Learning」,提出了端到端的问答系统 COREQA,它基于编码器-解码器(Encoder-Decoder)的深度学习模型,针对需要多个事实才能回答的复杂问句,引入了拷贝和检索机制,从不同来源,利用拷贝、检索和预测等不同词汇获取模式,获得不同类型的词汇,对应复杂问句中答案词汇的不同部分,从而生成复杂问句的自然答案。
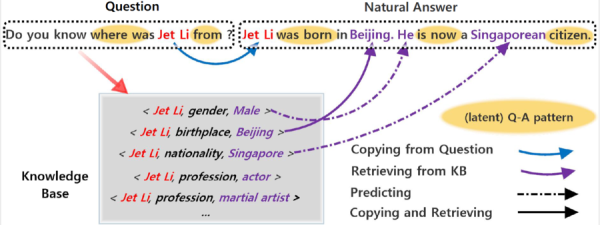 那么具体是怎么做的呢? 这里以“你知道李连杰来自哪里吗?” 这个问题为例来说明:
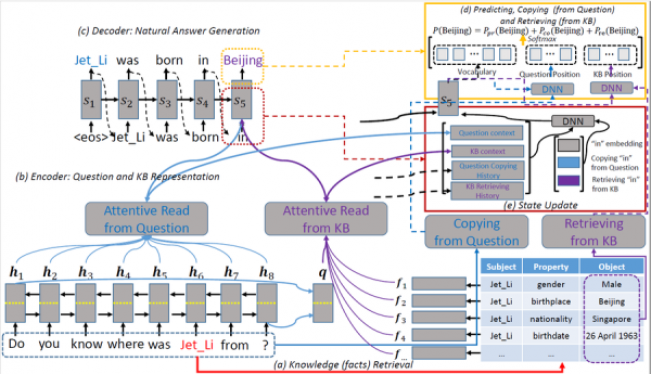
1. 知识检索:首先要先识别问题中的包含的实体词。这里我们识别出的实体词是:李连杰。然后根据实体词从知识库(Knowledge Base,KB)中检索出相关的三元组(主题,属性,对象)。针对李连杰这个实体,我们可以检索出(李连杰,性别,男),(李连杰,出生地,北京),(李连杰,国籍,新加坡)等三元组。
2. 编码(Encoder):为了生成答案,我们需要将问题和检索到的知识编码成向量,以便后续深度生成模型利用。
问题编码:使用了双向 RNN(Bi-RNN),用两种方式来表示问题:一种是将两种方向 RNN 状态向量拼在一起,得到向量序列 Mq;另外一种方式是把每个方向 RNN 的最后一个向量拿出来拼在一起,得到向量 q,用来整体表示问题句子。
知识编码:使用了记忆网络(Memory Network),对知识检索阶段得到的知识三元组分别进行编码。针对一个三元组,用三个向量分别表示各部分,再将它们拼接在一起,变成一个向量 fi 来表示这个三元组,用 Mkb 表示所有三元组向量。
3. 解码(Decoder):接下来根据答案和知识的编码向量来生成自然答案。自然答案虽然是词序列,但是不同的词可能需要通过不同途径获得。例如:对于上述问题的答案“李连杰出生在北京,它现在是一个新加坡公民。”,词语“李连杰”需要从源问句中拷贝得到,实体词“北京”,“新加坡”需要从知识库中检索得到,而其他词如“出生”、“在”,“现在”等需要通过模型预测得到。因此,这里在标准的序列到序列(Sequence-to-Sequence)模型基础上,融合了三种词语获得模式(包括拷贝、检索和预测),用统一的模型对其建模,让各种模式之间相互竞争相互影响,最终对复杂问题生成一个最好的自然答案。
为了检验模型的效果,论文分别在模拟数据集(由 108 个问答模板规则构造的问答数据)和真实数据集(从百度知道获取的 239,934 个社区问答数据)上进行了实验,在自动评估和人工评估上均取得了不错的结果。
谈到以后的工作,何世柱博士表示:“ COREQA 模型目前还是过于依赖学习数据。从实验结果可以看出,在模拟的人工数据上几乎可以有完美的表现,但是在真实的数据上还是差强人意。究其原因还是该模型本质是对原始数据的拟合,学习一个输入问题(词序列)到输出答案(词序列)的映射函数,特别是非实体词(即,不是拷贝和检索得到的词)常常预测得不准确。这是该模型最大的问题,我们计划加入一些外部的人工知识对模型进行调整,对现有模型进行改进。另一个不足是目前只能利用三元组形式表示的知识库,并假设答案实体就是三元组的 object 部分,其实该假设对很多问题并不成立,另一个可能的改进方向就是利用不同表示方式的知识库。另外,该模型也可以应用于机器翻译等任务,可以让语言生成模型能外部知识资源进行交互。”
而对于问答系统未来的发展,何世柱博士也有一些自己的的看法:“据我了解,真实的工程实践上,问答系统还是使用模板和规则,很少或者根本不会用到统计模型,更别说深度学习的模型了。而目前在研究界,问答系统几乎全部采用深度学习模型,甚至是完全端到端的方法。究其原因,我个人认为问答系统是一个系统工程,而不是一个纯粹的研究任务,目前研究界对问答系统还没有一个统一的范式(不像信息检索、机器翻译、信息抽取等任务),因此,未来问答系统可能需要总结出一个或几个通用范式和流程,可以分解为若干子任务,这样会更易于推动问答的研究发展。另外,问答系统效果无法达到实用,其问题还没有分析清楚,是知识资源不完备,还是知识表示的异构性,或者是理解自然语言问题的挑战?最后,我认为,问答系统这类需要大量知识的任务,在数据规模难以大规模扩展的情况下,融合统计模型和先验知识(萃取的知识库、语言知识、常识等)是可行的发展方向。”
那么具体是怎么做的呢? 这里以“你知道李连杰来自哪里吗?” 这个问题为例来说明:
1. 知识检索:首先要先识别问题中的包含的实体词。这里我们识别出的实体词是:李连杰。然后根据实体词从知识库(Knowledge Base,KB)中检索出相关的三元组(主题,属性,对象)。针对李连杰这个实体,我们可以检索出(李连杰,性别,男),(李连杰,出生地,北京),(李连杰,国籍,新加坡)等三元组。
2. 编码(Encoder):为了生成答案,我们需要将问题和检索到的知识编码成向量,以便后续深度生成模型利用。
问题编码:使用了双向 RNN(Bi-RNN),用两种方式来表示问题:一种是将两种方向 RNN 状态向量拼在一起,得到向量序列 Mq;另外一种方式是把每个方向 RNN 的最后一个向量拿出来拼在一起,得到向量 q,用来整体表示问题句子。
知识编码:使用了记忆网络(Memory Network),对知识检索阶段得到的知识三元组分别进行编码。针对一个三元组,用三个向量分别表示各部分,再将它们拼接在一起,变成一个向量 fi 来表示这个三元组,用 Mkb 表示所有三元组向量。
3. 解码(Decoder):接下来根据答案和知识的编码向量来生成自然答案。自然答案虽然是词序列,但是不同的词可能需要通过不同途径获得。例如:对于上述问题的答案“李连杰出生在北京,它现在是一个新加坡公民。”,词语“李连杰”需要从源问句中拷贝得到,实体词“北京”,“新加坡”需要从知识库中检索得到,而其他词如“出生”、“在”,“现在”等需要通过模型预测得到。因此,这里在标准的序列到序列(Sequence-to-Sequence)模型基础上,融合了三种词语获得模式(包括拷贝、检索和预测),用统一的模型对其建模,让各种模式之间相互竞争相互影响,最终对复杂问题生成一个最好的自然答案。
为了检验模型的效果,论文分别在模拟数据集(由 108 个问答模板规则构造的问答数据)和真实数据集(从百度知道获取的 239,934 个社区问答数据)上进行了实验,在自动评估和人工评估上均取得了不错的结果。
谈到以后的工作,何世柱博士表示:“ COREQA 模型目前还是过于依赖学习数据。从实验结果可以看出,在模拟的人工数据上几乎可以有完美的表现,但是在真实的数据上还是差强人意。究其原因还是该模型本质是对原始数据的拟合,学习一个输入问题(词序列)到输出答案(词序列)的映射函数,特别是非实体词(即,不是拷贝和检索得到的词)常常预测得不准确。这是该模型最大的问题,我们计划加入一些外部的人工知识对模型进行调整,对现有模型进行改进。另一个不足是目前只能利用三元组形式表示的知识库,并假设答案实体就是三元组的 object 部分,其实该假设对很多问题并不成立,另一个可能的改进方向就是利用不同表示方式的知识库。另外,该模型也可以应用于机器翻译等任务,可以让语言生成模型能外部知识资源进行交互。”
而对于问答系统未来的发展,何世柱博士也有一些自己的的看法:“据我了解,真实的工程实践上,问答系统还是使用模板和规则,很少或者根本不会用到统计模型,更别说深度学习的模型了。而目前在研究界,问答系统几乎全部采用深度学习模型,甚至是完全端到端的方法。究其原因,我个人认为问答系统是一个系统工程,而不是一个纯粹的研究任务,目前研究界对问答系统还没有一个统一的范式(不像信息检索、机器翻译、信息抽取等任务),因此,未来问答系统可能需要总结出一个或几个通用范式和流程,可以分解为若干子任务,这样会更易于推动问答的研究发展。另外,问答系统效果无法达到实用,其问题还没有分析清楚,是知识资源不完备,还是知识表示的异构性,或者是理解自然语言问题的挑战?最后,我认为,问答系统这类需要大量知识的任务,在数据规模难以大规模扩展的情况下,融合统计模型和先验知识(萃取的知识库、语言知识、常识等)是可行的发展方向。”
上一篇:混合云的容量扩展与功能添加





